assimilaate · memristors · ai-hardware · edge-ai
Chapter 1: Transforms will be Assimilated
Ship synapses. Stream transforms. Forget weights.
By Alex Nugent ·
A synapse is not a weight. It is a physical adaptive communication element. In Knowm world, it’s a memristor pair. A synapse unites memory and processing, and the only way to ship it is via snail mail.
Present-day AI runs on weights, or more precisely on our ability to compute them and move them around. We now spend absurd amounts of energy scraping the internet and human knowledge to iteratively learn what those numbers should be. Then we spend still more energy hauling them back and forth through networks and memory hierarchies so a model can consult that learned experience during inference. After awhile it starts to feel obvious that the weights must be the thing that matters.
Weights don’t matter. They are a means to an end. What matters is transforming one neural activation into another. And while it is true that synaptic weights are largely responsible for mediating the transform, there is no deep reason to communicate weights—not for distribution and not for inference.
To head off some of you at the pass I am not saying that AI of the future will work like we do, where every individual is tasked with their own internal learning. It’s far more interesting and powerful than that. Let me give you a metaphor to meditate on and hopefully knock you into another attractor.
Do you think that you are (only) the totality of the atoms that compose you? The atoms of that sandwich you had for lunch last week are now partially integrated into your body and will be expelled in a variety of ways, from days to months. Every atom that composes you right now will likely be replaced long before you die. You—and all living things—are Theseus’s Ship sailing from birth to death across the ocean of life. You are activations of energy flowing through a plastic container. When you remove those activations the atoms that temporarily compose your body will disintegrate into a pile. So let me ask you again. Do you think that you are only the atoms that compose you?
Now that we’ve shaken off the card-carrying eliminative materialists, let me assure the rest of you that what you will read in this blog series is nuts-and-bolts. I am not only going to explain how this all works, I will build it and I will put it on the internet. It’s not metaphorical and it’s not abstract. So let me quickly give you a description on how I believe the future of AI will work. May it serve as a waypoint marker on what might be a wandering (and hopefully interesting) walk in the future articles on this website.
Datacenters, the same ones we have now and likely a few more of them, will spend tremendous amounts of energy integrating more information than you can possibly conceive from every corner of the earth. That information will be computed into models that closely resemble what we have now. These models will be tweaked architecturally from time to time, more now, less later, as we arrive at a description of a near-optimal universal intelligence substrate. The models will be trained continuously, day after day. These models will not be used directly for inference. Their weights will not be copied to inference machines and those inference machines will not shuttle weights back and forth between memory and processing cores. Rather, the transforms will be represented as sparse activation address tuples (AATs), communicated to billions of edge devices near continuously at a tiny fraction of the bandwidth required to move weights, where they will direct the self organization of a variety of physical synaptic substrates of various ages and model numbers via a process I call assimilation. Assimilation will be fast—much faster than downloading weights. It will usually be done at night or in the off hours alongside active self-repair and more traditional security updates, but also interwoven with active inference if down time does not permit. Local copies will differentiate slightly to further optimize to their local environment without any supervision. Billions of semi-autonomous and autonomous platforms will gather information of every imaginable flavor and upload what’s new back to the cloud, where it will be integrated and disseminated across the fleet before the day is done.
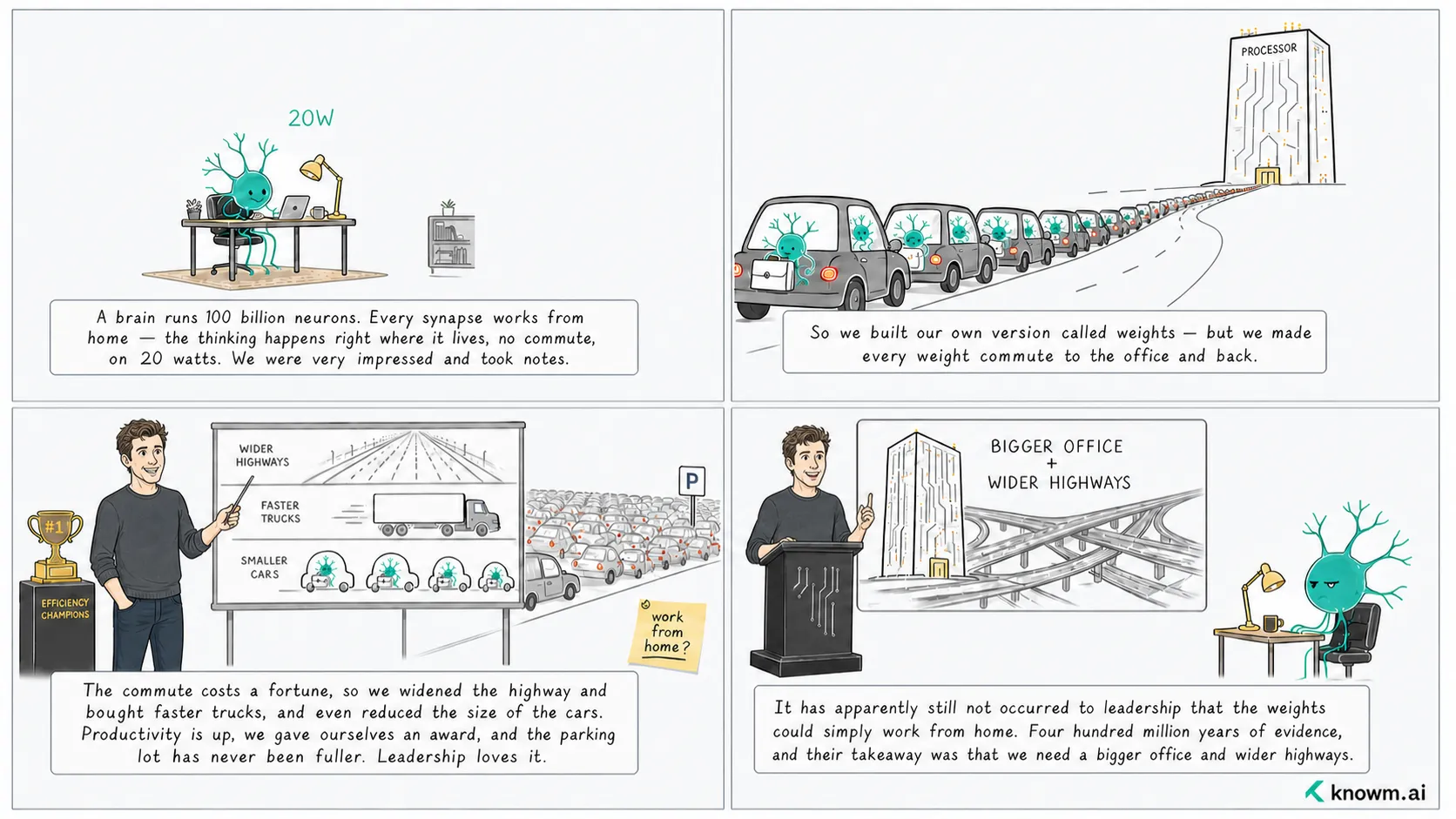
The Cost of Moving Weight#
A modern neural network is full of learned, weight-bearing transforms: embedding tables, dense projections, attention query/key/value and output matrices, feed-forward weight matrices, convolutional kernels, state-space parameter matrices, etc. This is the machinery that turns one representation into another. The normal deployment model treats those transforms as weight tensors to be copied and moved, both for distribution to inference infrastructure but also within inference memory hierarchies.
At the scale of biology (of which modern foundation models have not even remotely touched) moving weights is brutally expensive. You have to store them, transmit them, verify them, synchronize them, move them through memory hierarchies during every inference, and keep enough high-bandwidth infrastructure nearby to keep the whole thing fed. At frontier scale, this concentrates intelligence in data centers and makes them bleed for memory and energy. It’s not a coincidence that we are facing an energy and memory crisis while the AI race heats up. It’s not surprising that chips are going wafer-scale. By accounting for the energy of moving weights, we can see clearly where this is all headed:
Here, N is the number of values being moved, b is bits per weight value, r is the access rate, and the rest is the ugly physical cost of charging wires across distance at a voltage. We will fight every term in that equation. We will lower the voltage. Shorten the wires. Reduce precision. Make activity sparse. But the largest move is conceptual: stop moving the damn weights in the first place.
Copying a dense weight layer scales with the whole matrix: roughly mn values. Teaching behavior with examples scales with the number of examples and the width of the communicated neural state. A 4096 by 4096 layer at 16 bits is about 268 Mbits of weights. Fifty dense input-output examples are about 6.5 Mbits before sparse encoding. ASSIMILAATE pushes the communicated object smaller still: sparse Activation Address Tuple (AAT) pairs for assimilation, sparse AAT traffic during inference, and local conductance states (‘the weights’) emerging from the plastic synaptic substrate and are never communicated.

ASSIMILAATE is built around a blunt and simple rule: don’t move weights. Not for deployment, or updates or inference. Never. The teacher can be enormous and cloud-bound and integrate information from millions of sources. The edge targets are synchronized by receiving examples of what a transform does, the sparse compact activations themselves. The weights emerge, as they must, through intrinsic plasticity. The synapses are physical. They stay local. The transforms are real. They are communicated. The weights are ephemeral. They emerge in place to satisfy the transform under the constraints of the hardware.
The mistake is treating a massive object as though it were weightless. A 4096 by 4096 weight matrix at 16 bits is 268 Mbits. It has inertia. You feel it every time you haul it through memory for another inference pass. The answer is not to make the weights lighter—to quantize the bits, prune the matrix, or compress the tensor. The answer is to acknowledge it’s heavy and to stop lifting it. Let the light thing travel.
Why Memristor Hardware Seems Awkward#
When you really dive into the nuts and bolts of the memristor hardware literature it’s a bit painful and awkward. The classic (or ignorant) picture is beautiful on the surface: store weights as analog conductances in a crossbar, apply voltages to rows, read currents from columns, and get vector-matrix multiplication in one shot. On paper it is glorious—and it was one of my first patents over twenty years ago. It’s the sort of idea that comes from enthusiasm but little experience. When you get your head out of the clouds and into the lab, this beautiful picture develops ugly wrinkles and falls apart. You need precise conductance programming. You need DACs and ADCs. You have sneak paths and parasitics. You have device variation, drift, read disturbance, line resistance, temperature effects, and topology mismatch. It’s a mess, and it does not work. Oxide ReRAM, CBRAM, phase-change — every one of them gets dragged through the same gauntlet, and every one of them loses some teeth.
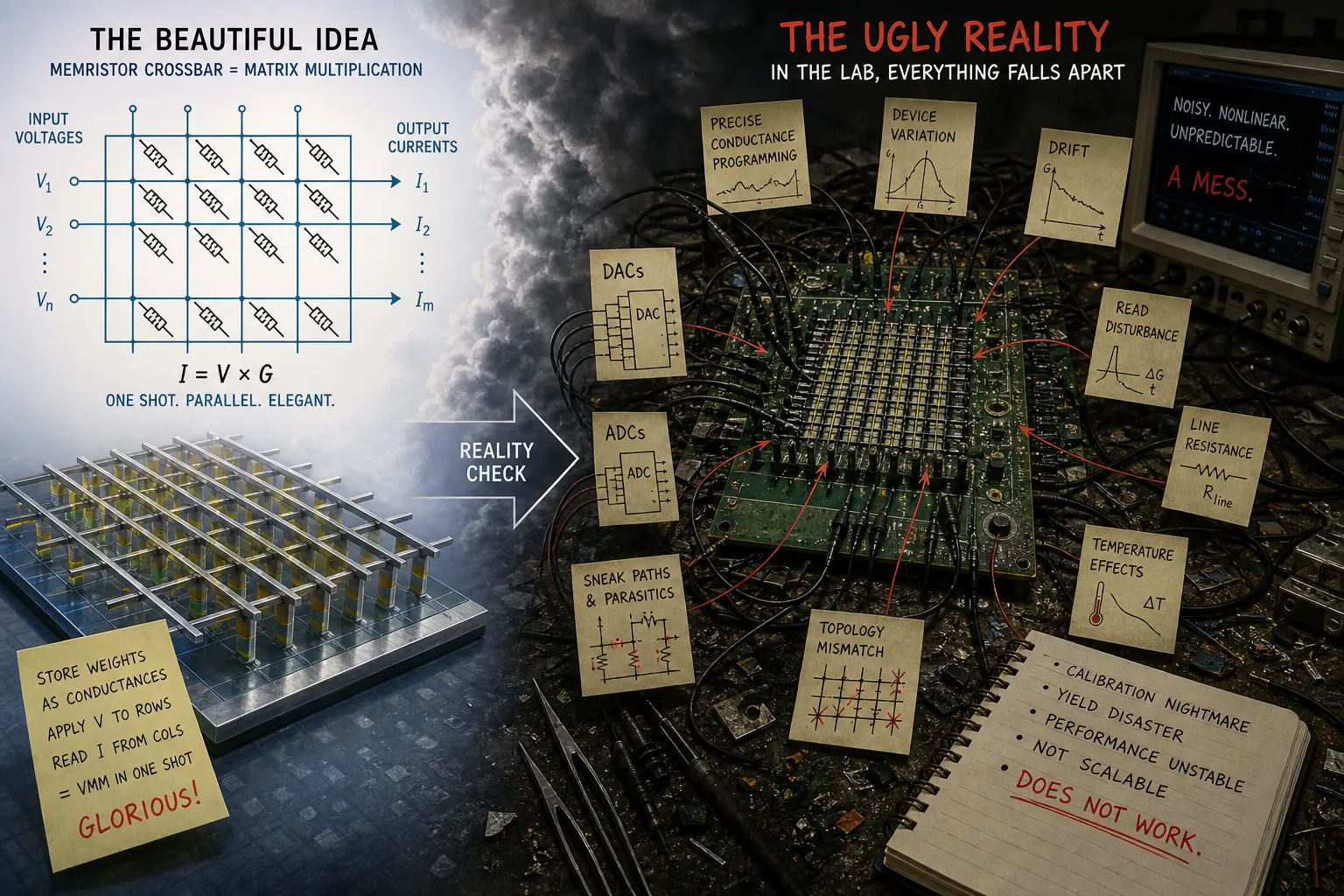
The problem is not memristors. The problem is the computational model they’re being asked to serve. The memristor field has been trying to force a stochastic, plastic, physically alive device into the role of a static precision resistor — and then complaining that it misbehaves. Stochastic switching is a defect if your target is exact weight replication. Drift, variation, parasitics — same story. Whether the physics fights you or works for you depends entirely on what you are asking the hardware to do. We have been asking the wrong thing because we don’t really understand what weights are.
What ASSIMILAATE Changes#
ASSIMILAATE stands for Analog Synaptic Systems Implementing Memristor-Integrated Learning and Activation Address Tuple Encoding. It will be the recurring theme for this particular blog series, and I will build it publicly. Yes, it’s a dope backronym. No, I am not apologizing for it. Yes, I am going to turn it into a verb. The central move is to communicate neural state as AATs rather than dense analog values. An AAT is an ordered tuple of activation addresses. Each address is interpreted locally by a receiving neural lane as a synaptic selection. The same communicated AAT can be sent to many targets, and each target interprets it through its own local synaptic organization. AATs are the ultra-light-weight neural activation patterns that I believe are necessary and sufficient to enable AI at scale. If this is not making sense it’s OK. If you continue with me on this journey you will learn all about it in great detail as I build and simulate. I will teach you what I know, and perhaps (hopefully) you will take it farther.
During assimilation, a teacher model produces input-output AAT pairs for its internal transforms. The teacher model can be a normal ML model (subject to some architectural constraint at least for the moment) and its internal activations are converted to AATs via vector quantization methods or—also possible but less likely at first—the model can be trained from the start to utilise AATs. The target hardware presents the communicated AAT pairs to its neural lanes and the adaptive synaptic substrate “decodes” them into local transform states through local learning. The differential memristor synapses adapt in-situ until the local hardware emits the desired output AATs. No weights are transmitted. No attempt is made to force the target’s microscopic conductance state to match the teacher’s weights. Two devices can implement the same transform with different learned conductance states, even in the presence of damage and degradation. The teacher publishes its desired behavior. The target instantiates behavior on its synaptic substrate by streaming AAT pairs.
At scale, a cloud teacher can publish AAT training streams for a transform—a new capability or an update. Edge devices subscribe to the streams they need, assimilate the behavior locally, validate against held-out examples, and report compact convergence metadata. The devices do not have to share identical microscopic conductance states. This is how billions of people will run frontier models in their pockets and vast fleets of robotic minds will synchronize and share knowledge continuously—without turning the planet into a sea of dystopian datacenters.
Ultra-Low-Energy Inference#
Once a transform has been assimilated into local memristive hardware, the learned state (the weights) never move. They are not streamed from DRAM for every inference, or held in SRAM locally. Information is streamed to synaptic cores as AATs, and the receiving neural lanes adapt and return the transformed AATs. Memory access is synaptic access is compute is the transform. All becomes one when the distance between memory and processing becomes zero and we allow our hardware to adapt.

Dense digital systems are very good at arithmetic, but they pay dearly for data movement. ASSIMILAATE spends movement only on the neural state that must be communicated, while leaving the learned physical state in place. The future will need vast numbers of manufactured adaptive synapses, but their learned states will not be shipped around as data. Synapses become abundant, local, adaptive, fault-tolerant physical resources, and the transforms become the communicable object, implied by the activation patterns. The adaptive synaptic substrate makes it all possible. I am reminded of the song lyrics. “And it’s ironic too, because what we tend to do, is act on what they say, and then it is that way”. Catchy tune—and a bit prophetic.